Improving audio fidelity for HF single sideband (and AM ) Microphone content has been split to another page |

Although somewhat different animals, AM-FM audio processing techniques can be applied to ssb transmission to achieve some improvement in the audio quality. The first step is to ask what exactly we are trying to achieve? Maximum loudness equates to the highest rms value audio waveform, usually produced by a combination of dynamic compression and clipping. Maximum fidelity minimizes distortion and maximizes frequency response. There is significant controversy about unnecessarily wide occupied voice channel bandwidth being " more than your fair share." You have to ask yourself whether 50 Hz to 15 kHz audio frequency response is necessary or advisable. I can't answer that but I can tell you that a100 Hz to 7kHz voice bandwidth sounds very natural. In the case of ssb, adding just a bit more to the 2.4 or 2.7 kHz normal bandwidth, say 500 Hz, adds a lot to the perceived quality. Back to our basic question: Are we after maximum intelligibility (through a noisy medium), or the most natural sound? You can't maximize both, but you can get close - loud and clean audio processing can be done - radio broadcasters do it all the time. And for voice, the complexity is much less. |
|||
Why does SSB have inferior audio quality compared to AM and FM? Theoretically, (and practically with elaborate methods) ssb can sound just as good as AM, but two factors make it more difficult: First, traditional ssb generation has been done using a balanced modulator feeding a narrow-bandwidth crystal filter. Frequency response is limited due to the filter. A wider filter could be used for more transmit audio bandwidth, OR with modern radios using dsp filtering, frequency response can be opened up. Secondly, and perhaps more significant is that, with a suppressed carrier, very precise tuning with bfo and product detector is needed but impossible by manual methods, and this not only creates a slight voice pitch offset, it creates another interesting effect - a vocal vowel resonance at, say 400 hertz has natural harmonics at 800 and 1200 hertz - precise multiples of the fundamental tone. With a 10 hertz mis-tuning, these are not multiplied but additively shifted - 410, 810, and 1210 hertz - and they are no longer harmonically related. That's why it sounds funky. This latter problem has been largely overcome by injecting a pilot tone (or burst) into the transmit audio at a precisely known frequency, and using a phase-lock-loop on the receive end to ensure correct tuning - remember those early space flight communications with the embedded "beep" in each transmission? |
|||
Primary to all our further discussions is understanding some key audio quality metrics. It's important to be able to individually identify undesirable artifacts before we can find a remedy. Our goals for loud and clear audio are:
The most important factors for low distortion ssb and extended frequency response ssb are (essentially) choice of rig, and optimal drive level adjustment to an amplifier - which I personally can't do without seeing the rf envelope on an oscilloscope. While surfing some "hi-fi" ssb and am web sites, I see some hams have virtual recording studios grafted onto their hamshack, including very expensive microphones, but no scope to get maximum peak output without clipping (or negatively over-modulating in the case of am). I can only presume that these folks are unfamiliar with its use. The scope is a great tool in adjusting for best quality. Two-tone testing with a spectrum analyzer measures the non-linearity of the ssb generation and amplification, which causes audio distortion, but isn't practical for most hams. -- The other major quality determining element (perhaps the one which most people perceive first) - limited primarily by the rig is the audio frequency response. Traditional ssb transmitters generate double sideband using a balanced modulator, then pass only usb or lsb through a crystal filter, the width of which determines the maximum audio bandwidth (frequency response). Typically this is quantified at the -3 dB points, for example, on the bass end - 300 Hertz and, on the treble end - 2700 Hertz may be 3 dB below the center response. This does not mean that everything below and above are completely absent, but rather are rolled off with a more-or-less steep slope. And although this audio bandwidth is reasonable for voice intelligibility, it's far from natural sounding. A 2100 Hz bandwidth (300-2400) sounds even more unnatural. Many modern rigs using dsp generation with front-panel variable filtering, can pass lower than 200 hz and greater than 3000 hz at the -3dB points, which, assuming a receiver is used which has appropriately wide IF bandwidth and audio response, makes a noticeable improvement. But you quickly reach a point of diminishing returns. Keep in mind that as you increase receiver bandwidth, your signal-to-noise ratio is reduced. Personally, I think 200 to 3200 Hertz sounds pretty good for sideband. Response below 100 Hertz is generally undesirable, allowing hum, structurally transmitted table taps, P-pops, etc., to mix with the voice and unnecessarily contribute more intermodulation frequencies. -- Achieving good Signal-to-noise ratio in this context, essentially translates to how much RF energy is getting to the receiver - to compete with noise and QRM. The peak (or average / RMS depending upon your method) audio energy, divided by the noise energy, within the receiver's audio passband (lotsa qualifiers here) equals signal-to-noise-ratio ("S/N"). Often, because you cannot get rid of the noise during actual measurement Signal + Noise divided by noise is used, which is close to the same for decent S/N. As an example for a 20 dB S/N, the audio power is 100 times that of the noise - (or 10 times the voltage). This 20 dB figure is pretty good, but we always like better - high-fidelity SN is subjective and quite relative to the context, but for the sake of comparison, a decent AM broadcast station will transmit at least 60 dB S/N - received SN will be less, subject to distance, propagation, and interference. The primary S/N limiting factor is transmitter power and antenna gain. More is better. Increasing SSB peak transmitter output from 100 watts to 1500 helps the received audio signal-to-noise ratio by almost 12 dB. For all amplitude modulation methods including ssb, the effect is linear. Transmitter audio dynamics processing (compression / limiting) increases the average audio level, increasing the average transmitted power. It does this while maintaining the same peak level - decreasing what's called the crest factor. In essence, it quickly raises the low-level portion of speech, and compresses, limits, or clips the highest parts. By its nature this introduces some harmonic distortion which is counter-productive to increasing intelligibility. But, when done in moderation, it can sound very clean and will increase average power considerably. In the early 70's, an enterprising broadcast engineer named Mike Dorrough introduced his DAP 310 to the AM broadcast market. It combine many innovative features using op-amp circuitry, including two back-to-back 1n914 diodes used as a final stage clipper. Subsequent to the adoption of the DAP, it was commonly said that it could make a 1 kilowatt station sound like 5 Kw. Bob Orban was another pioneer. Audio dynamics processor design is now a well-developed art form optimizing the loudness / distortion tradeoff. |
|||
Transmitter
frequency response can be measured with an audio tone generator
(with an appropriate resistor pad reducing it to mic level) slowly
sweeping the 50hz - 5khz audio range at about 30% transmitter
output power, while noting the wattmeter. When 15% power
is shown, the -3 dB point is indicated. |
|||
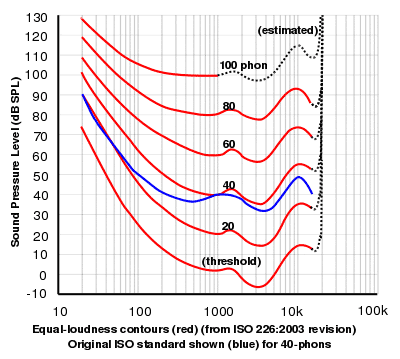 |
The equal-loudness curves shown at left are derived from the original Fletcher and Munson human hearing research. The 2 kHz to 4 kHz droops essentially define the presence band which add intelligibility to speech. | ||
I alternate between the Kenwood's internal audio processing which is reasonably clean, and using just the alc with no clipping. The AP makes for louder, denser audio, but the frequency response is somewhat peculiar. While normally any clipping of the waveform is taboo in pro audio circles, the reality of HF communications is that it can gain you better signal-to-noise through higher average transmitted power, at the tradeoff of slight peak distortion. It is however an outright distortion generator, so must be used sparingly to preserve good quality - typically, the uppermost one to four dB of the previously dynamically compressed audio is clipped, depending upon the loudness / distortion tradeoff you're looking for. With AM modulation, broadcasters generally use asymmetrical clipping, set to brick wall clip downward (negative) modulation peaks at 95% to avoid splatter, and clipping the positive (louder!) excursions at 125%. Most ham AM transmitters are pretty poor positive modulators. FM broadcasters, - even those with formats that don't allow aggressive processing, (not many) use some amount of clipping to prevent overmodulation. |
|||
|
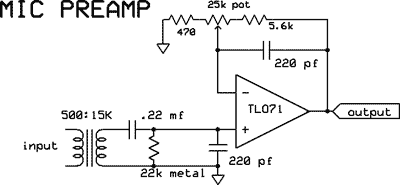
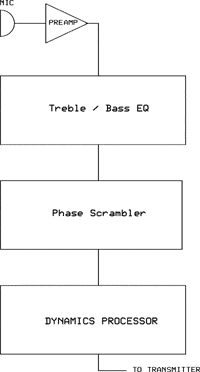
In a future article, we will actually design and construct a broadcast style audio processor optimized for amateur radio. | The overall block diagram of a typical high fidelity processor is shown at left - sometimes a clipper will follow. A really good preamp can be put together from a dedicated $8 Analog Devices chip. A very similar unit from THAT corp is here. For ham audio, the performance of a TLO71 or LF351 op amp is more than adequate, and is what I use - for improved RF immunity, I like transformer isolation, using high quality mic transformers like the UTC ouncer 0-8 series with shield and shock isolation. This traditional approach works very well, but good transformers can be expensive. Jensen is another good brand of transformer. | |
 |
|||
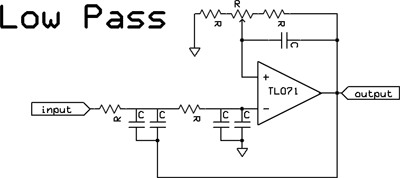
| Just after the mic preamp, it's a good idea to band limit the audio to near what will eventually be transmitted. This prevents gain-reduction caused by spectral energy which won't make it all the way through the transmitter chain. It also minimizes the frequencies unnecessarily present which will contribute to intermodulation distortion products. The low corner is typically set between 50 to 300 Hertz, and the high roll off set at 3200 to 7000, depending upon your mode and your goals. The pots in the circuits shown control the passband flatness / ultimate slope tradeoff. These are shelving filters - more sophisticated filtering will be presented in a future construction article. | 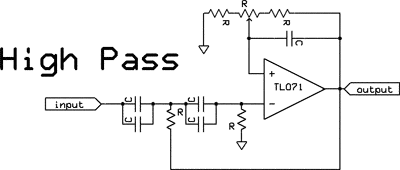 |
||
The "ouncer O-8" audio transformer is ideal for the mic preamp input. This one has an additional shield to minimize ac hum pickup, and a rubber shock mount to minimize microphonics.
|
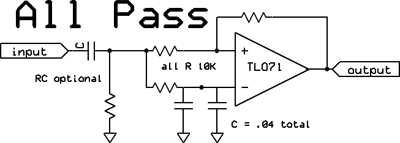
NOTE: each of these three drawings show the + and - inputs to the Op-amps reversed. |
||
An ALL-PASS? Speech as well as certain music is often very asymmetrical - that is to say the positive portion of the waveform can be much different than the portion below the zero line. Dynamic processing for ssb and fm will be more exacting and efficient with improved symmetry - that's why virtually all modern broadcast audio processors use some means of phase-rotation. The technique imparts variable phase shift across the audio passband, particularly in the bass-midrange region - about 500-700 Hertz. With many types of natural-source audio, symmetry is in fact improved. What actually happens is that the midrange and treble peaks are "rotated" off of the "tops" of the bass peaks, so the two no longer add. For full-carrier AM, a negative clipper may ultimately follow to limit negative modulation to about 95%, while letting positive peaks supermodulate. With a single person's voice, all-pass phase rotation may or may not be favorable - by selecting the best polarity, we typically want the positive peaks to be stronger and exceed 100% modulation if the transmitter is capable of it. This phase rotation method was the basis of Leonard Kahn's famous Symmetra-Peak AM pre-processor, introduced for broadcast in the 50's. The block diagram for his patent is shown at right, as well as a depiction of the effect on the audio waveform. For SSB, where both positive and negative audio peaks create RF equally, symmetry contributes to higher rms level. All-Pass, phase rotation, and "phase-scrambler" are essentially synonymous. The Op-Amp circuit shows one section. Sometimes two or more are cascaded. |
 |
||
 |
|||
No audio discussion would be complete without mentioning tubes. Understand why we like tubes - it is NOT because they are superior to modern technologies. The current state of audio equipment merchandising is sad; in no other segment of electronics can you find more psychoacoustic snake oil being successfully sold. The market appears to be dominated by non-technical sales types selling to even less-technical "audiophiles." "Punchy", "smooth" or "that warm sound" replace established technical metrics. I estimate that over half the money spent on "high-end" equipment is entirely wasted on hyped and often misleading features and performance specs. A perfect example is the retro-fad use of tubes in audio stages. One computer motherboard manufacturer even boasts about their "tube" output amplifier for its built-in sound card output stage. The only thing that seems to matter is if they can sell them. There are those who will swear by their $500 tube microphone "preee" (pre-amplifier) instead of a cheaper, modern op amp version. Most of these folks mean well, but typically lack understanding of analog electronics basics. Having personally done proof-of-performance testing on tube broadcast equipment ( high-dollar professional gear ) in the 70's, and since then, many generations of solid-state equipment, let me bear witness to the fact that, with all other things being equal, modern solid-state devices excel at audio, and tubes can only come close at best, and are awful at worst. One argument often parroted is that tubes clip less abruptly, therefore producing distortion which is not as harsh sounding; (This from the guitar amplifier crowd.) Certainly this is true, but the argument is irrelevant because when properly operated, one should never reach the clipping point in a normal amplifier - if you do this by overdriving a stage, then you're intentionally introducing harmonic and intermodulation distortion, the prevention of which is what our best efforts are all about. Tubes are microphonic, noisier, are in a constant state of deterioration, and due to the high impedances involved, necessarily require transformers, which unless very high quality, add low-frequency distortion. And otherwise sane people pay extra for these features! "...but I can hear a difference! " is frequently cited as the toobie mantra. I don't mean to suggest that analytical listening has no place, but when subjective tastes trump actual measured distortion and tonal colorations, we're ignoring reality. And we are hearing differences - just as the 17 year-old generation, accustomed to hearing low-bit-rate, poorly encoded MP3 distortion, think something is wrong when they hear the original non-bit-reduced .wav file. People have expectations, and some folks, for whatever reason, just prefer unnatural sounding audio. So, the idea of tube audio being superior in any way other than replicating nostalgic tonal coloration is pure and simple nonsense. This coloration (increased harmonic distortion, noise, and typically, but not always, reduced treble frequency response) can be replicated with modern methods if this is really what you want. Similarly there are other well-meaning folks who will pay huge amounts for gold-plated, de-oxygenated speaker cables. "A fool is born every minute" - P.T. Barnum. Having said that, let me also mention that well-designed tube audio equipment, in good condition, can serve quite satisfactorily for general purpose work - pretty high quality broadcast sound was generated this way for many years. But compared to modern devices, it's more expensive and won't perform as well. Rule-of-thumb: don't believe audio discussion which avoids actual technical metrics like signal-to-noise ratio, frequency response, harmonic and intermodulation distortion, but is instead liberally spiced with hyperbole. Meaningless, often misleading terms are typically used by salespeople to persuade you to buy - or by newbies who are ignorant of the actual technical methods. I'll summarize by saying that outside of certain high-power RF and a few other very specialized applications, the only good argument for tube equipment is for nostalgia - and for precisely that reason, (and to demonstrate that I'm not a toob-hater) I own a Johnson Viking Ranger, a Collins 75A3, and am currently restoring a 1937 National NC-101X.and a 1931 SW-3. I also take pictures of nice looking RF tubes |
|||

{kind=link}
{kind=link}
Back to W4NEQ.com main page